Demo
Dataset
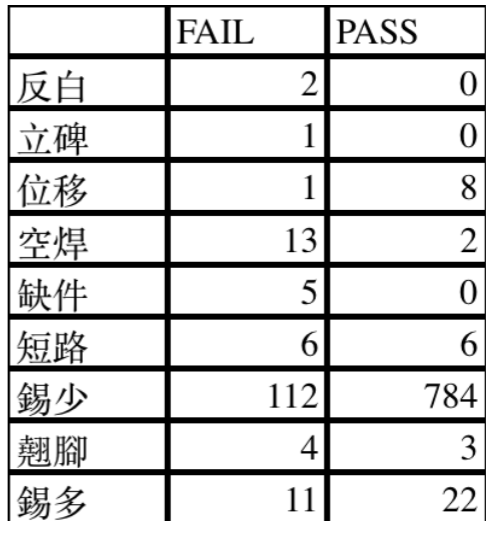
There are many types of data, and we focus on 錫少(Too little tin) and 錫多(Too much tin).
However, there are many difficulties of the dataset, such as fail-pass bias, images are not clean, and same class different type issue.
At first, we wanted to separate the area out by focusing on green in HSV space, but it didn't work like what we thought.
After some trials, we decided to do it without separating the area out.
Approach
We chose Mobile Net due to the limited computation resources.
And we have implemented data augmentation by scaling, filpping and shifting.
We also implemented multi-step transfer learning according to data size:
First, from ImageNet to 錫少(Too little tin), and second, from 錫少(Too little tin) to 錫多(Too much tin).
Result
In 錫少(Too little tin) case, fail class has 111 images and pass class has 962 images.
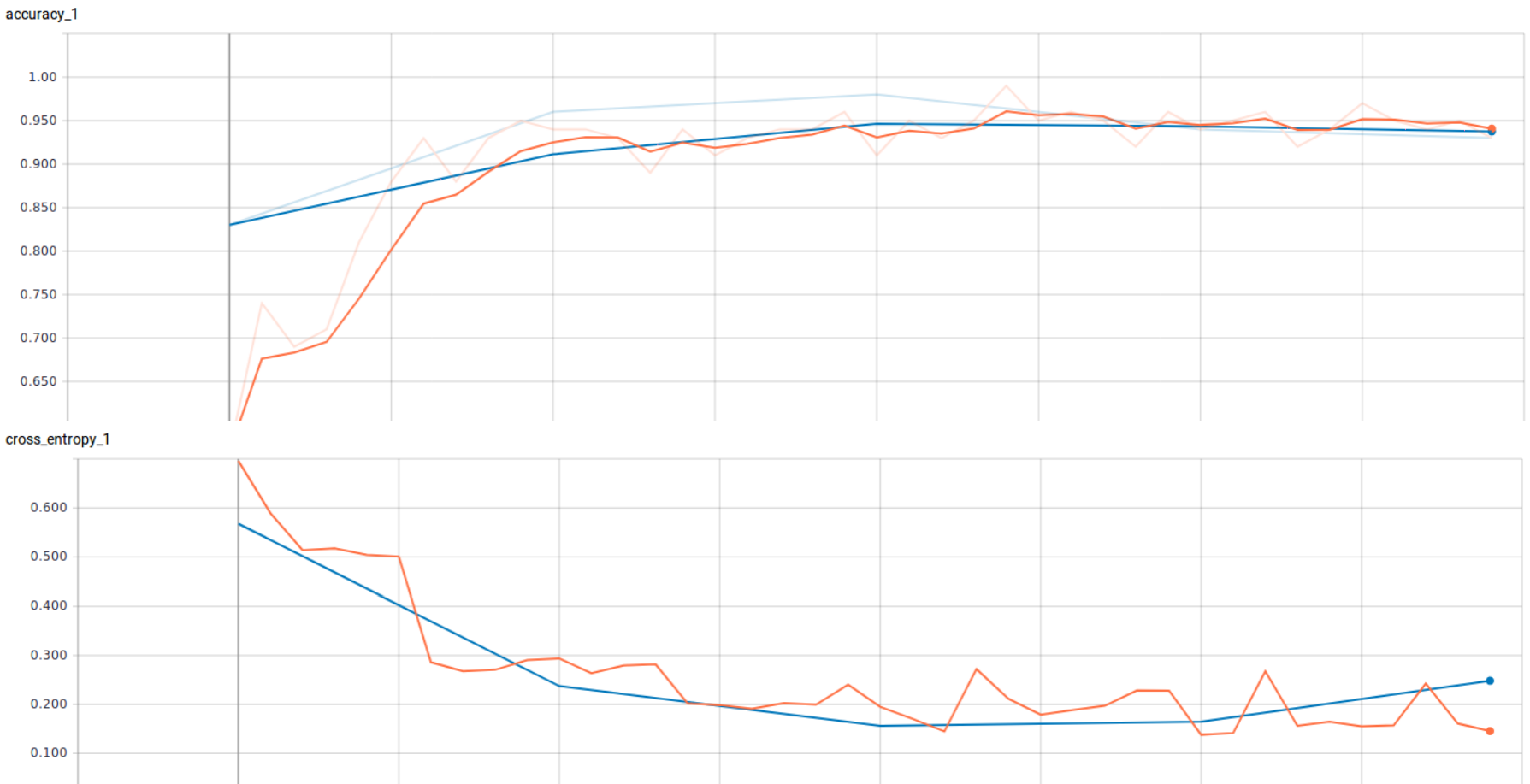
After retraining for 40 steps, we choose 88 testing images, and get 96.5% accuracy. The learning curve is on the first curve plot above.
In 錫多(Too much tin) case, fail class has 20 images and pass class has 22 images.
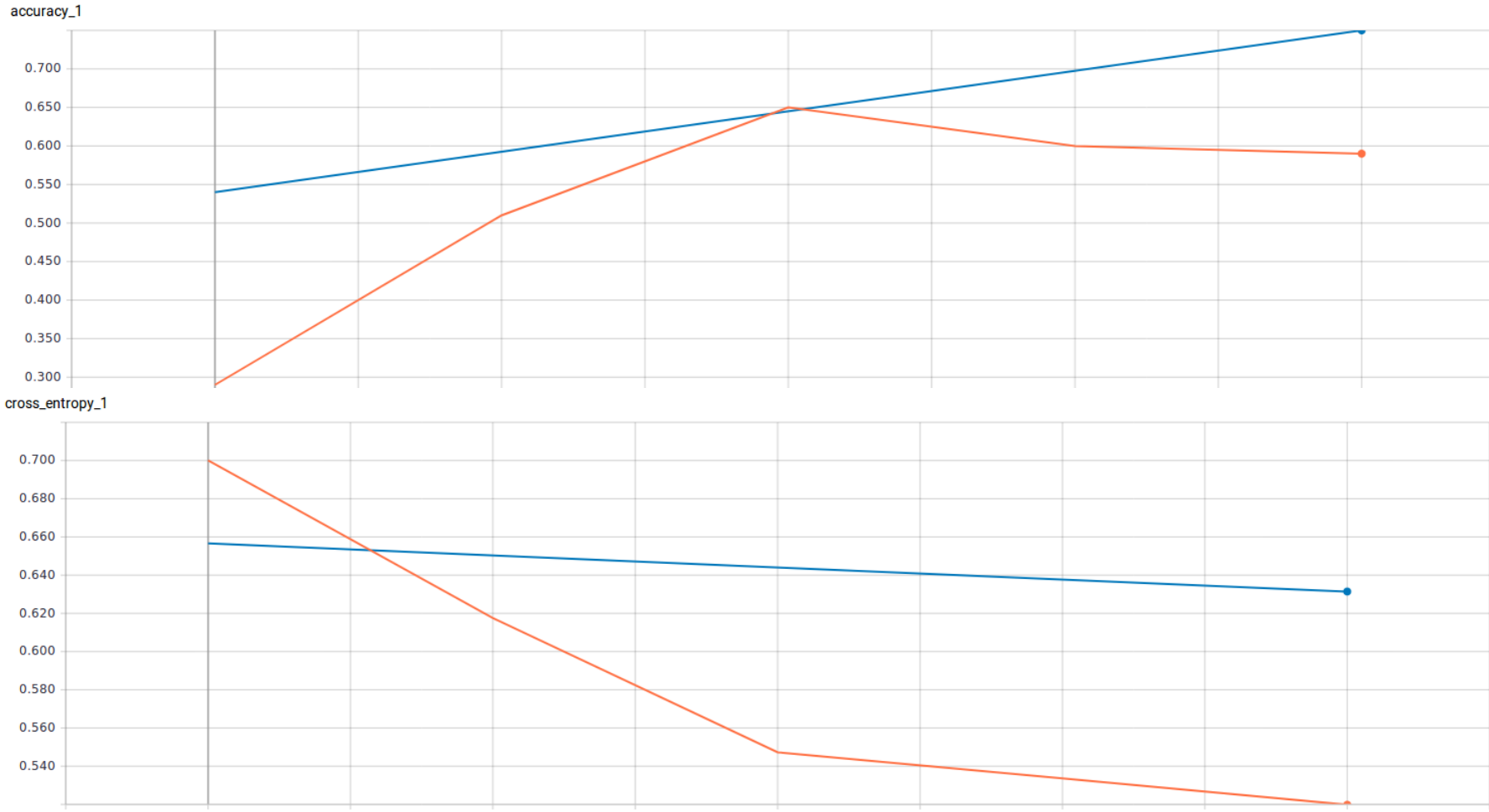
After the second-step transfer learning, we choose 2 testing images, and get 100% accuracy. However, it turns out that the output probability is not so sure(51% v.s. 49%). The learning curve is on the second curve plot above.
The result of t-SNE visulization is on the plot below. We can say that different cases in one same class (e.g. less fail[2] and less pass[3]) can be seperated well, but different cases in all classes can not.
Future Work
Data cleaning is needed, because outputs from AOI machine is not clean. However, it may takes effort to come up with a good algorithm.
Also, if the hardware is good enough, we can try more complicated model structure such as ResNet50, VGG19, ... etc..
The output of AOI machine also includes some failure messages. it should be much better if we implement sentence embedding improvement.

Contact us
We’d love to chat about this project, send us an email.